
A case study on using voice technology to assist the museum visitor
Steven Moore, The Museum of Modern Art (MoMA), USA, Diana Pan, The Museum of Modern Art, USA, Manish Engineer, Seattle Art Museum, USA
Abstract
In 1952, Bell Laboratories developed what is considered the first speech recognition system: Audrey (Pinola, 2011). It could only understand numbers and it required the speaker to pause between words. Since then, other systems followed, each with a growing vocabulary set but each with different limitations on usage. It was only in the 2000s that speech recognition made a significant leap forward, first with the Google Voice Search application and Google Now, and then very closely followed by Apple's Siri. Mobile devices offered an ideal platform for practical uses of hands-free speech recognition tools. Both Google tools and Siri also relied heavily on the power of cloud-based computing, the ability to draw upon a massive amount of data pertaining to speech search queries, and an ever evolving and constantly learning analysis of one's own unique speech patterns, all of which helped these tools to produce the best possible response to a user’s query. While not mainstream yet, the improved accuracy, as well as the quirkiness of these tools helped increase overall awareness of voice activated technologies in solving basic user questions. As voice activated smart devices become more mainstream with consumers, we at The Museum of Modern Art (MoMA) in New York City, have taken steps towards analyzing its potential uses on both a consumer and an enterprise level to assist our Museum community. In order to do this, we focused on the Amazon Echo. In this How-To session we will cover how we integrated the Amazon Echo with the MoMA Collections database and built it a new "skill" for answering queries related to modern and contemporary art at MoMA. The purpose of this session is to introduce voice activated technologies with a concrete and functioning prototype. We will walk through the technical implementation details of our prototype and discuss what MoMA considers the potential use cases at our Museum.Keywords: voice technology siri amazon echo
Introduction
In late 2014, the Amazon Echo was introduced as a consumer oriented smart speaker and in-home assistant. A year later, on Black Friday 2015, the Echo was the top selling item over $100 on Amazon (Amazon, 2015), and by April 2016, sales of the product reached 3 million units. The steadily increasing popularity of the Echo, with its constantly growing set of “skills,” is a result of very smart marketing by Amazon, and also reflects a growing awareness by consumers and businesses alike of voice activated technologies not dissimilar to Siri. In early October 2016, Google announced their own smart speaker assistant, the Google Home, and two months later, opened its platform up through its Actions on Google functionality for third party software applications integration.
As voice activated smart devices become more mainstream with consumers, we at The Museum of Modern Art (MoMA) in New York City have taken steps towards analyzing its potential uses on both a consumer and an enterprise level to assist our museum community. In order to do this, we focused on the Amazon Echo. In this How-To session we will cover how we integrated the Amazon Echo with the MoMA Collections database and built it a new “skill” for answering queries related to modern and contemporary art at MoMA. Specifically, we will cover:
- Basics: Amazon Alexa’s skills, intents, utterances, and slots
- How voice user design differs from Web design
- How to work with the Amazon Alexa API
- A general look at smart assistants and what we learned
- Museum use cases and what’s next for MoMA
The purpose of this session is to introduce voice activated technologies with a concrete and functioning prototype. We will walk through the technical implementation details of our prototype with Amazon’s Echo and discuss generally what MoMA considers as potential use cases at our museum.
Basics: Amazon Alexa Skills, Intents, Utterances, and Slots
It is helpful to understand specific vocabulary before talking about Alexa’s technical capabilities and limitations. It mainly comes down to four things: Skills, Intents, Utterances, and Slots.
- Skill: A Skill is something that Alexa is capable of doing, like “Alexa, play Adele,” or answering a question like “Alexa, what is the weather?”
- Intent: An Intent is a something that your Skill does or answers. For example, “Alexa, ask MoMA how do I get there?” is the Directions Intent. “Ask MoMA about Picasso” is the Artist Intent. The end user is not concerned with Intents, but it is part of the vocabulary when we talk about building an Alexa Skill.
- Utterances: Utterances are what the person says to Alexa. You classify each Utterance as an Intent type, for example:
- BathroomsIntent Where are the bathrooms
- BathroomsIntent Where are the restrooms
- HoursIntent When are you open
- HoursIntent When can I go for free
- DirectionsIntent Where is MoMA
- DirectionsIntent Which subway do I take to get to MoMA
- Slots: Slots is the Alexa word for a variable in an Utterance. So part of the Utterance is fixed and the Slot fills in for the part that changes, specifically artist and title in MoMA’s case, for example:
- ArtistsIntent How many works do you have by {Artist}
- ArtIntent Where is the art work {Title}
In the examples, you substitute the {Artist} Slot with the artist’s name, same for {Title} in the art work title. Slots are optional.
How to work with the Amazon Alexa API
A skill has two parts: the Skill Service and the Skill Interface (Figure 1). The Skill Service is implemented by a developer. The Skill Interface is a set of options that you configure in the Alexa Skills developer portal (https://developer.amazon.com/alexa). Together, they make up a working Skill.

Figure 1: Skill Service and the Skill Interface
Skill interface
The Skill Interface is the easier part, but one of the inputs is the HTTPS endpoint where the Skill Service is located. We will cover that later.
After logging into the Alexa Skills developer portal and adding a new Skill, all of which is self-explanatory, you will see a set of seven steps as shown in Figure 2 (https://developer.amazon.com).

Figure 2: Skill Interface
Rather than explain every detail, below you will find the notable parts that you may need to consider for each section:
- Skill Information: Skill Type is Custom
- Interaction Model: The most important part of the Skill Interface. This is where you put in the Intent Schema and Sample Utterances. It will look like Figure 3.

Figure 3: Interaction Model
- Configuration: Where you define the service endpoint. Most museums will leave “Account Linking” as “No.” “Account Linking” allows your Skill to link to users’ Amazon accounts, for purchasing or ordering services, for example. It also means the Skill certification process will be much more detailed.
- SSL Certificate: You can use a self-signed certificate for testing, but a public Skill requires an SSL certificate from a trusted certificate authority that is approved by Amazon. This covers the standard certificate authorities, but check the developer portal if you purchase from a lesser-known vendor.
- Test: Essential for testing and debugging. The Service Simulator allows you to test Alexa by typing in Utterances and seeing what kind of response comes back. It also has a Voice Simulator so you can hear what it sounds like with Alexa.
- Publishing Information: Small and large icons in specific sizes are needed for the Skill, otherwise self-explanatory.
- Privacy & Compliance: Self-explanatory. Privacy and Terms of Use policies are optional unless you use Account Linking; then it is mandatory to pass certification.
Skill Service
This is the code part. A Skill can be written in any programming language that can run on an HTTPS web server and return JSON as the response. In these examples, we are using .NET and C#.
Many of the introductory examples suggest using AWS Lambda and Node.js. This is a great way to start, but it does not really apply to most museums and database-driven content because the database servers are often in-house. AWS Lambda is cloud-based so integrating your internal database would be fairly complicated. It is possible to implement Alexa in a museum setting without database-driven content. If all the questions have fixed responses, then AWS Lambda is a good choice and the whole process is much easier. It is also possible to hard-code curatorial responses for specific works or artists, but it means that you create a specific Intent for each artwork/artist. This would apply at say, The Dali Museum, where you would create an Intent that retrieves information for Salvador Dali; or, a museum has a renowned work like Vincent van Gogh’s The Starry Night (MoMA) and you anticipate many questions for just that work. In our examples, we anticipate any artwork on view (because location in the museum is part of the response) and any artist.
At MoMA, we implemented ten Intents. Most intents have hard-coded responses. This paper is concerned with showing steps for the database-driven responses (bold below):
- Exhibitions
- Events*
- Films*
- Artists
- Art
- Bathrooms
- Hours
- Directions
- Food
- Stores
*can be database driven but are not for now
There are also built-in Intents such as Stop, Cancel, Help, and Launch, but that is covered in most introductory examples so we will not look at that.
Let’s look at the Exhibitions Intent.
The first step is to imagine the kinds of things users will ask Alexa about exhibitions at MoMA. They will also ask the same question in a number of different ways (ask about, tell me about, what are, etc.). In these examples we use just one form; but certifying your Skill requires adding all the variations you can think of. Below are two examples.
“Alexa, ask MoMA about exhibitions.”
“Alexa, ask MoMA about exhibitions {Date}”
What is {Date}? This is a built-in Slot that allows the user to say things like “tomorrow,” “next week,” or “in March.” When we looked at the Interaction Model above, you can see these phrases in the Sample Utterances section (Figure 3).
Amazon’s technology takes the voice input and matches it to the Skill name (in this case MoMA) and the Sample Utterance. The Skill Service’s main responsibility is to provide the response, in a standard JSON format, back to Amazon.
For MoMA, that all starts with SQL.
The exhibitions example is a good place to start because the slot/variable for Date is almost always understood by Alexa. The Date returned by Alexa needs to be parsed, which is not an insignificant task (see GitHub repository https://github.com/smoore4moma/tms-api for details), but the SQL is straightforward:
SELECT DISTINCT E.ExhTitle, E.DisplayDate FROM Exhibitions E INNER JOIN ExhVenuesXrefs EX ON E.ExhibitionID = EX.ExhibitionID WHERE (EX.ConstituentID = 1234) AND (EX.BeginISODate <= @p_start_date) AND (EX.EndISODate >= @p_end_date)
The exhibition title and date are then used in the Alexa response, which looks like this:
{Alexa says} “Here are the exhibitions you asked for. Bouchra Khalili: The Mapping Journey Project. Bruce Connor: It’s All True…”
And the visual “card” you see on the mobile Alexa app or at alexa.amazon.com shows the following (Figure 4):

Figure 4: visual “card” in Alexa mobile application
So…how do you do that?
First understand that the following is really intended for developers and technical people, but it is easy to follow along. At a conceptual level, here are the steps:
- The user says something to Alexa.
- Alexa identifies the Utterance and associates it with a Skill name (MoMA) and a Skill intent (I want to know about exhibitions).
- Alexa creates a POST request to your Skill service. The POST lets the service know the intent type and variables, if any.
- The Skill service pulls data from the database for the specific intent and creates a JSON response which it sends back to Alexa.
- Alexa reads the response aloud.
The Code
All of the code discussed in this section is available on GitHub:
https://github.com/smoore4moma/tms-api
The GitHub repository is neither owned nor endorsed by The Museum of Modern Art (MoMA), and MoMA takes no responsibility for its contents.
On a code level, the Alexa Request and Response follows a fixed JSON format, specifically:
Alexa Request
Alexa will POST something like the JSON below to your skill service. Alexa provides this, but you must be able to consume the JSON. See GitHub repository for object definition under Models, AlexaRequest.cs:
{
"session": {
"sessionId": "SessionId.2e634962-101c-49df-b84c-a654de74b75f",
"application": {
"applicationId": "amzn1.ask.skill.15a86908-4360-49aa-adb7-foobar"
},
"attributes": {},
"user": {
"userId": "amzn1.ask.account.alsofoobar"
},
"new": true
},
"request": {
"type": "IntentRequest",
"requestId": "EdwRequestId.8d213991-4a28-4a5a-a776-a64e3483f02a",
"locale": "en-US",
"timestamp": "2016-12-15T18:43:09Z",
"intent": {
"name": "ExhibitionsIntent",
"slots": {
"Date": {
"name": "Date"
}
}
}
},
"version": "1.0"
}
Again, the code’s responsibility is to consume the POST data from Alexa and handle the kind of question appropriately, then provide a response. It does this with code called the Intent Handler. As mentioned previously, MoMA has ten different Intents. If the request name is ExhibitionsIntent, which it is above, then we will call ExhibitionsIntentHandler. The handler is the part that goes to the database and runs the SQL. It looks like this:
// Exhibitions
private AlexaResponse ExhibitionsIntentHandler(Request request)
{
string dateValue = "";
if (request.SlotsList.FirstOrDefault(s => s.Key == "Date").Value != null)
dateValue = request.SlotsList.FirstOrDefault(s => s.Key == "Date").Value.ToString();
string conn_data = ConfigurationManager.ConnectionStrings["MyConnectionString"].ConnectionString;
SqlConnection sql_conn_data = new SqlConnection(conn_data);
sql_conn_data.Open();
// Get exhibitions
SqlCommand getAlexaExhibitions = new SqlCommand("procMomaAlexaExhibitions", sql_conn_data);
getAlexaExhibitions.CommandType = CommandType.StoredProcedure;
getAlexaExhibitions.Parameters.Clear();
getAlexaExhibitions.Parameters.Add(new SqlParameter(@"@p_alexa_date", SqlDbType.VarChar, 50) { Value = dateValue.ToString() });
SqlDataAdapter sda = new SqlDataAdapter(getAlexaExhibitions);
DataSet ds = new DataSet();
sda.Fill(ds);
sda.Dispose();
DataTable dt_exhs = ds.Tables[0];
int m_dt_exhs_ct = dt_exhs.Rows.Count;
var output = new StringBuilder("Here are the exhibitions you asked for. ");
var outputCard = new StringBuilder("Here are the exhibitions you asked for.\n");
foreach (DataRow dr_exh in dt_exhs.Rows)
{
output.Append(dr_exh["ExhTitle"].ToString() + ". ");
outputCard.Append(dr_exh["ExhTitle"].ToString() + ", " + dr_exh["DisplayDate"].ToString() + "\n");
}
sql_conn_data.Close();
var response = new AlexaResponse(output.ToString());
response.Response.Card.Title = "Exhibitions";
response.Response.Card.Type = "Standard";
response.Response.Card.Text = outputCard.ToString();
return response;
}
Alexa Response
The Response is a class with all of the variables defined in the Alexa standard:
For MoMA it looks like the JSON below, which is returned to Alexa. Alexa reads the Response text aloud and shows the card text on a device. See GitHub repository for object definition under Models, AlexaResponse.cs:
{
"version": "1.0",
"response": {
"outputSpeech": {
"type": "PlainText",
"text": "Here are the exhibitions you asked for. How Should We Live? Propositions for the Modern Interior. A Revolutionary Impulse: The Rise of the Russian Avant-Garde. Francis Picabia: Our Heads Are Round so Our Thoughts Can Change Direction."
},
"card": {
"text": "Here are the exhibitions you asked for.\n How Should We Live? Propositions for the Modern Interior, October 01, 2016 - April 23, 2017\nA Revolutionary Impulse: The Rise of the Russian Avant-Garde, Saturday, December 03, 2016 - Sunday, March 12, 2017\nFrancis Picabia: Our Heads Are Round so Our Thoughts Can Change Direction, November 21, 2016 - March 19, 2017",
"title": "Exhibitions",
"image": {},
"type": "Standard"
},
"reprompt": {
"outputSpeech": {
"type": "PlainText"
}
},
"shouldEndSession": true
},
"sessionAttributes": {
"memberId": 0
}
}
The next step: art and artists
Once you can do one database-driven response, then you can do just about anything in a database. For art and artists, there are two caveats that are particular to Alexa. The first is Alexa is still learning how to pronounce non-English names and words, and many museums have non-English artist names and artwork. Even with common examples, Alexa can have issues. For example, the renowned sculptor Richard Serra is more likely to be interpreted as Richard Sarah. And you will get no response, or an incorrect one.
The other caveat is the need to have a search index as part of your SQL or use a NoSQL option like Elasticsearch or Solr. At MoMA, we use SQL Server Full-Text Index to query the data needed for the response. For example, if I say this:
“Alexa, ask MoMA about the artwork The Starry Night”
Alexa will include this in the Request:
“intent”: {
“name”: “ArtIntent”,
“slots”: {
“Title”: {
“name”: “Title”,
“value”: “starry night”
}
}
The ArtIntentHandler will then take the “value” part of the Alexa request – “starry night” – and use it in a SQL statement to get the data:
Note: @p_searchterm is ‘starry AND night’
SELECT {24 fields}
FROM {11 tables}
WHERE CONTAINS(OT.Title, @p_searchterm)
CONTAINS is a SQL Server convention used with Full-Text Index. The SQL is filtering the data where the title contains “starry” and “night”.
As long as Alexa understands “starry” (not story, starfleet, starting, etc.) and “night” (not knife), then you get a valid response that looks like Figure 5:
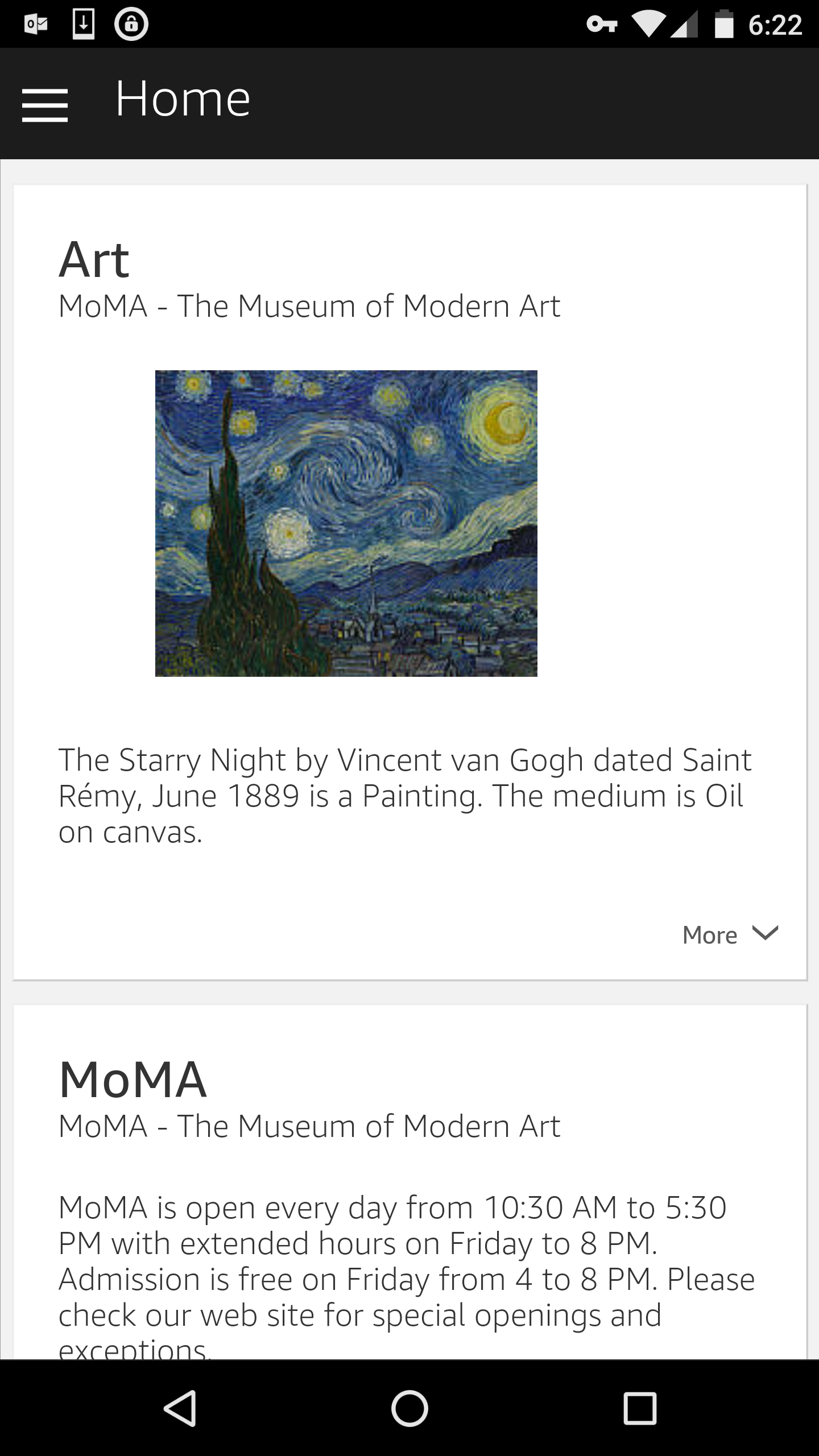
Figure 5: Alexa “card” response for object
Technology
MoMA uses The Museum System by Gallery Systems, specifically TMS 2016 R2. The database platform is SQL Server 2014. Snapshot replication is used to create a daily copy of the production database, with just selected tables. The Alexa service uses the copy, not production. The compiled .NET code is hosted on Windows Server 2008 R2 running IIS.
A look at smart assistants and what we learned
In the few short months since Google Home became generally available, many comparisons between it and Amazon’s Echo have already been made. While most focused on consumer oriented features such as smart home partnerships, speaker quality, personal assistant capabilities, and music streaming options, to name a few, we looked at the Echo, the Home, and also Siri based on their ability to integrate with and present museum-specific content to enhance MoMA’s visitor experience. Here is what we learned:
1. Equal amongst these devices, and as mentioned earlier, one major limitation is simply the devices’ availability in English only. All of these devices could not comprehend non-English names or titles posed within a question (see previous Richard Serra example), nor respond properly with such. In the case of Amazon’s Echo, MoMA is actively working with Amazon on a project that will help teach Alexa the names and titles of non-English artists and artwork.
2. Domains, actions, skills, oh my. These are all the different ways to integrate data sources or applications with the various smart assistants. We’ve already examined up close Alexa’s skills and intents and how we integrated Alexa with MoMA’s collection database. Apple’s Siri allows for a higher level of categorization in “domains” (e.g., ride booking, photos, messaging) with the “intents” as supported functions within a domain (e.g., “send message,” “search photos,” “book a ride”). “Extensions” allow apps in those domains to integrate to Siri to support the intents (e.g., extensions are built into the Uber or Lyft apps so Siri can book a ride on one of those services). The list of supported domains and their intents is still evolving. In the Google Home, one can build “conversation actions” which would hand a user off, for example, to an Uber conversation agent who can have a seemingly natural, contextually aware, though still limited, conversation to search for and book a ride.
While none of these products are anywhere near mature yet, each integration option shows tremendous promise for a future where a true “natural” conversation can occur. Also of importance, the Google Home and Amazon Echo already have simplistic contextual awareness. Proper responses are made for questions such as “tell me about Jackson Pollock,” followed by “when was he born?” without having to repeat the name Jackson Pollock. One can envision a day where there is an arts “domain,” or when the home becomes an “art curator” and the “intents” or “skills” cut across multiple museum data sources to answer a question such as “tell me about abstract expressionist artists” followed by “where can I view such artworks?” and other related questions. At present though, the conversation with each of these devices is still awkward and exposes their technical limitations.
Museum use cases and what’s next for MoMA
Having walked through an implementation with the Echo and MoMA’s collections database, it is clear that the such voice activated smart assistants are not ready yet for mainstream consumption, without at least some amount of guidance and limitation. Introducing such tools into a public space offers new audiences participatory opportunities while also posing new social interaction questions, as demonstrated recently at the Barnes Foundation (Bernstein, 2016). Nevertheless, these are some potential uses that may be worth exploring in a museum and arts context:
- An internal tool to help museum staff more quickly learn and find information about an artwork, including information that is not available to the public. This would be an alternative to a browser based tool and at best would shave minutes off what would otherwise be a browser search.
- An external tool for exhibition and art information. As we work with Amazon to solve the non-English name pronunciation issue, we hope to eventually release our integration as a new Skill for Alexa. Observing how this Skill is then used by any owner of an Echo may be informative not just to MoMA, but to the arts sector.
- A public-facing tool in the museum placed in common areas such as a museum’s charging stations or cafes to be used to serve general information, and also to help us gather information and learn about visitor interests. Since Amazon saves all queries, this could be useful information to review and help us provide better messaging to visitors based on what is being asked. A public-facing tool, however, introduces some practical challenges, such as physically locking down the device or restricting use of the tool to specific Skills, to name a few.
- A public-facing in-gallery assistant to provide information about very specific exhibitions, artists, and artworks. Since we know the Echo has some limitations in non-English responses, we can work around this and experiment with it in a limited and controlled fashion to see if this is a viable in-gallery tool.
- A public-facing alternative tool to aid in accessibility options.
Acknowledgements
This paper acknowledges the contributions and collaborative work between individuals in the MoMA Information Technology department and also Amazon Echo’s product development teams.
References
Amazon. (2015). Press Release: Record Weekend for Amazon Devices—Up 3x Over Last Year, with Millions of Devices Sold, 2015. Consulted February 8, 2017. Availble http://phoenix.corporate-ir.net/phoenix.zhtml?c=176060&p=irol-newsArticle&ID=2119025
Apple. (2016). “Siri’s Domains and Intents.” Consulted December 12, 2016. Available https://developer.apple.com/library/content/documentation/Intents/Conceptual/SiriIntegrationGuide/SiriDomains.html
Apple. (2017). “Conversation Actions for Google Home.” Consulted January 27, 2017. Avaialble https://developers.google.com/actions/develop/conversation
Bernstein, S. (2016). “What Can Alexa Teach Us About the Barnes?” Medium. Consulted December 6, 2016. Available https://medium.com/barnes-foundation/what-can-alexa-teach-us-about-the-barnes-21154d68700c#.v08qjcf4k
Pinola, M. (2011). “Speech Recognition Through the Decades: How We Ended Up With Siri.” Consulted February 8, 2017. Available http://www.pcworld.com/article/243060/speech_recognition_through_the_decades_how_we_ended_up_with_siri.html
Cite as:
Moore, Steven, Diana Pan and Manish Engineer. "A case study on using voice technology to assist the museum visitor." MW17: MW 2017. Published January 26, 2017. Consulted .
https://mw17.mwconf.org/paper/a-case-study-on-using-voice-technology-to-assist-the-museum-visitor/