
DigiBird: On the fly collection integration supported by the crowd
Chris Dijkshoorn, Vrije Universiteit Amsterdam, the Netherlands, Cristina-Iulia Bucur, Vrije Universiteit Amsterdam, The Netherlands, Maarten Brinkerink, Netherlands Institute for Sound and Vision, The Netherlands, Sander Pieterse, Naturalis Biodiversity Center, The Netherlands, Lora Aroyo, Vrije Universiteit Amsterdam, The Netherlands
Abstract
Online cultural heritage collections often contain complementary objects, which makes integration between heterogeneous collections a worthwhile effort. In order to do so, objects have to be adequately described. Crowdsourcing in cultural heritage is evolving to be an approach to collect annotations at scale, but faces challenges regarding sustainability and structured use of results in the context of existing collections. The DigiBird project integrates four distinct nature-related collections and serves as a hub for crowdsourcing systems that extend collection data. An Application Program Interface (API) is built on top of the DigiBird pipeline, enabling institutions to embed integrated results in their online collections.Keywords: collection integration, crowdsourcing, engagement strategies, cross-institutional collaboration
Introduction
Collection objects from different cultural heritage institutions, when shown together, can strengthen the message conveyed individually. Traditionally this has been achieved by curating exhibitions. But the increase of available cultural heritage data sets a premise for collaborations that do not require physically moving the objects. Deciding on the right objects to show requires the metadata of collection objects to be adequate and interoperable. Describing collections objects is, however, a time consuming and costly process. Crowdsourcing is evolving to be a valuable approach for cultural heritage institutions to collect metadata and engage their audience. Since the seminal Steve.Museum project (Chun et al., 2006), ample best practices have been developed in the field of crowdsourcing in the cultural heritage domain (Oomen & Aroyo, 2011); however, current crowdsourcing initiatives face four challenges:
- Crowdsourcing initiatives are typically undertaken in isolation of other institutions and collection annotation processes;
- Crowdsourcing initiatives typically take a long time to collect the necessary annotation data;
- Crowdsourcing initiatives demand continuous promotional effort to maintain a steady user participation level;
- It is challenging for institutions to provide a structured process to incorporate the results of different crowdsourcing initiatives into their existing collection infrastructure.
In this paper, we present the results of experimenting with the DigiBird (http://www.digibird.org/) infrastructure that reinforces crowdsourcing initiatives and integrates four distinct nature-related collections by linking their crowdsourcing results. Two of these crowdsourcing platforms gather media: 1) Xeno-canto enables bird enthusiasts to collect and describe bird sounds; and 2) the Dutch Species Register allows nature enthusiasts to upload images of animals encountered in the Netherlands. The other two projects gather metadata for existing media collections: 1) the Accurator, a crowdsourcing platform used by the Rijksmuseum Amsterdam enables birdwatchers to add bird annotations to artworks; and 2) the Waisda? video labeling game from the Netherlands Institute of Sound and Vision allows people interested in a certain subject or domain (e.g. nature) to annotate videos related to their subject or theme of interest. The way we addressed the four crowdsourcing challenges in relation to these various collections is outlined below.
To tackle the first challenge concerning the isolation of the crowdsourcing initiatives, we created the DigiBird pipeline, which connects the abovementioned Dutch nature crowdsourcing projects, starting with birds as a proof of concept. DigiBird ingests, integrates and outputs data from several systems. A central request to DigiBird is transformed into separate requests, which are delegated to the underlying systems. Obtained results from the systems are combined and returned: the data is integrated by transforming it into one representation, which can be output in different formats. Harmonizing data from a multitude of systems that adhere to different standards proved to be one of the most challenging tasks of the project.
The second challenge, regarding the long duration of crowdsourcing data collection, was tackled by setting up centralized monitoring for the integrated systems. Since most crowdsourcing projects rely on voluntary contributions, the time it takes to collect sufficient data is unpredictable. Hence insights into the progress of the crowdsourcing process are of great value. The DigiBird pipeline supports sending queries that retrieve aggregated statistics, such as the number of contributors and contributions. This information is shown on a DigiBird monitoring dashboard, tailored to each platform and updated with real-time information.
To address the third challenge, relating to the necessary continuous promotional effort of the crowdsourcing initiatives, we incorporated mechanics that trigger participants with challenging crowdsourcing tasks. We approached this by setting up crowdsourcing campaigns revolving around specific domains, and inviting people to contribute by organizing events (Jongma & Dijkshoorn, 2016). Promoting crowdsourcing initiatives is essential for keeping contributors involved. At a later stage, data collected by the DigiBird pipeline can serve as input for continuously and automatically generating crowdsourcing tasks that incentivize contributors to keep sharing their knowledge. The DigiBird hub now serves as an overview of the systems, showing completed tasks.
In response to the final challenge with regard to the incorporation of crowdsourcing results into existing collections, we built the DigiBird API (Application Program Interface) on top of the DigiBird pipeline, which can be used by heritage institutions to embed the results of the combined crowdsourcing efforts into their online collections. The DigiBird API is already used by Naturalis Biodiversity Center to embed results on one of their sites, the Dutch Species Register.
Origin of the DigiBird project
Crowdsourcing projects tend to be undertaken in isolation. This was well illustrated during the panel discussion “Bridging the Natural Divide: Crowd-curation of Cultural Expressions Inspired by Nature” held at MCN2014 (Brinkerink et al., 2014). Four crowdsourcing projects from the Netherlands were presented, and each organization had developed its own system. While the initiatives all took different approaches to involving the crowd, they had one topic in common: nature. It became apparent that despite the different approaches, the collections are complementary and the profile of the user groups targeted for crowdsourcing showed considerable overlap. This sparked the idea of a collaboration that extended beyond one conference panel, in which the participating institutions could explore how the different projects could strengthen one another by integrating the results. Thus DigiBird hatched.
There are two dimensions in which the abovementioned crowdsourcing projects show big differences: media modality and the type of contribution by the crowd. Table 1 provides an overview of the collections and systems, mapped to these two dimensions. DigiBird includes media of three different modalities: sounds, images, and videos. Since artworks are often not images themselves, merely represented this way online, we split the artworks from images in the overview table. In the type of contributions we distinguish how crowdsourcing is used. Some collections exist of media objects contributed by the crowd, making it a crowdsourced collection. Other systems are used to extend the metadata of existing collections. In the remainder of this section we will discuss the individual collections and crowdsourcing methods in more depth.
| Type | Sounds | Artworks | Images | Videos |
| Collections | Rijksmuseum Amsterdam | Sound and Vision | ||
| Crowdsourced collections | Xeno-canto | Dutch Species Register | Stichting Natuurbeelden | |
| Crowdsourced metadata | Accurator | Waisda? |
Table 1: type of media provided by systems in addition to the crowdsourcing systems that are used to either gather collection objects or metadata describing existing objects
The Dutch Species Register (http://www.nederlandsesoorten.nl/) is a thesaurus of all multicellular species observed in the Netherlands since 1758. The register is hosted by Naturalis Biodiversity Center (http://www.naturalis.nl/) and as of January 2017 it includes 43,306 species, of which 9,644 have a corresponding image. These images are taken by amateur photographers, who upload them to the online platform. Once the images are uploaded, the depicted species and quality are validated by a group of experts coordinated by Naturalis. The register includes many images of birds, thereby making it a valuable addition to the DigiBird project. Through DigiBird, Naturalis is able to link this crowdsourced collection to both their own natural history collection and to similarly-themed cultural heritage collections from other institutions, to enrich the user experience and provide context.
Xeno-canto (http://www.xeno-canto.org/) is a foundation that aims to popularize bird sounds and recordings. An online community uploads and co-curates sounds, contributing to the goal to collect the complete sound guide of the birds of the world. As of January 2017, a total of 9,691 species have been recorded, covering over 90 percent of all described bird species known to exist. The foundation welcomes all sorts of (re)use of their bird sound collection, and they are always looking for enthusiastic people to further annotate the collection. The DigiBird project offers opportunities on both fronts.
The foundation Natuurbeelden (http://www.natuurbeelden.nl/) maintains a collection of nature videos from the Netherlands, hence the Dutch name which translates to “images from nature.” The videos are shot by professional filmmakers and contributed to the collection of the foundation in a raw and uncut format. The collection of the foundation is preserved and made available by the Netherlands Institute for Sound and Vision. Sound and Vision is also involved in the development of Waisda?, which is an online system that allows its users to annotate audiovisual archive material in the form of a game with a purpose (Gligorov et al., 2013). The goal of the game is to reach a consensus between players while they tag elements in videos. Tags are scored higher if an entry is confirmed by another player, or the tag matches a term from a controlled vocabulary. Loading the Natuurbeelden collection in Waisda? allows collecting additional metadata for the videos. The collected metadata and the DigiBird project helps Sound and Vision to explore the possibilities to take specific subject matter from their vast collection and connect them to relevant niches and other collections from other institutions.
The Rijksmuseum Amsterdam (https://www.rijksmuseum.nl/) collection includes over one million objects, providing an overview of Dutch art and history from the Middle Ages onwards. As of March 2016, 207,441 of these artworks have been digitized and made available online (Dijkshoorn et al., 2017). The museum realized that not all subject matter could be adequately described by its staff, since at times expert knowledge is required. Therefore, the crowdsourcing system Accurator was developed, in a collaboration of cultural heritage institutions and universities, who joined forces in the SEALINCMedia project (https://sealincmedia.wordpress.com/), which is part of the COMMIT/ program (http://commit-nl.nl). Accurator supports experts from the crowd to annotate images using structured vocabularies (Jongma & Dijkshoorn, 2016). Involvement of niche groups with a certain area of expertise is actively sought out by organizing campaigns with events tailored to the topic. Birds are one of these topics, and a birdwatching event was organized within the museum, making the crowdsourced data and Rijksmuseum collection a great addition to the DigiBird project.
The SEALINCMedia project was a research project that lasted for four years, focussing on getting crowdsourcing as a reliable, robust and effective method suitable for cultural heritage organizations. During these years, four PhD projects investigated different aspects of crowdsourcing: expert finding, trust, task recommendation, and interfacing. It was important to implement and deploy these methods as part of the heritage infrastructure and therefore the COMMIT/ program supported the DigiBird project as a valorization effort. The project ran for six months, during which two researchers from the Vrije Universiteit Amsterdam regularly worked at the participating cultural heritage institutions. In the remainder of this paper we discuss the results of this effort, starting with the DigiBird pipeline.
The DigiBird pipeline
It takes time to collect annotation data through crowdsourcing, and since most crowdsourcing projects rely on voluntary contributions, there is always a dependency on people willing to invest their knowledge and time. Within DigiBird we set three goals to reduce the time needed to obtain meaningful results from crowdsourcing efforts and make the crowdsourcing process more insightful and dynamic: 1) harmonization of complementary collection objects; 2) instantaneous availability of crowd contributions; and 3) the ability to monitor multiple systems in one dashboard. To achieve these goals we created a pipeline that ingests, integrates, and outputs data. A detailed overview of the architecture of the DigiBird pipeline (https://github.com/rasvaan/digibird_api) is given in figure 1. In this section we discuss the design rationale of the pipeline, focussing on request interpretation, data retrieval, data integration, and data output.
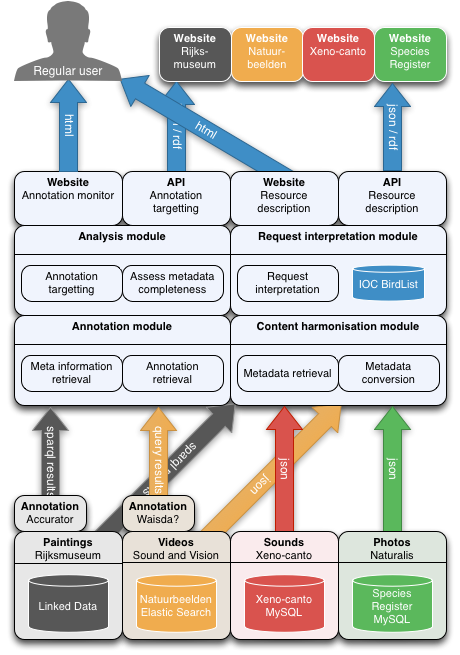
Request interpretation and formulation using structured vocabularies
Concepts from structured vocabularies can be of great value in determining what sort of request is made to the DigiBird pipeline and thereafter allows for correctly forwarding this request to the underlying system, through their respective APIs. This functionality is part of the request interpretation module, which disambiguates requests using the IOC World Bird List (http://www.worldbirdnames.org). This structured vocabulary includes almost 34,000 concepts, with corresponding scientific names and labels in 23 different languages. A request can either be formulated as a common species name (e.g. “Eurasian Magpie”) or a scientific name (e.g. Pica pica). This input is matched with a concept in the vocabulary with its corresponding identifier. Now, as the intent of the request is known, new requests have to be formulated that can be delegated to the underlying systems.
| Source system | Stichting Natuurbeelden |
Xeno-canto | Rijksmuseum | Accurator |
| Type of endpoint | API | API | SPARQL | SPARQL |
| Method | Text search | Concept search | Text query | Concept query |
| Query content | Ekster | Pica pica | Ekster | ioc:Pica_pica |
| Response format | JSON | JSON | SPARQL result list | SPARQL result list |
| Metadata integration | – === – |
rec === dc:creator |
creator === dc:creator |
creator === dc:creator |
Table 2: Overview of how data is obtained from four of the systems regarding the concept “Eurasian Magpie.”. For each institution, the supported methods of data retrieval have to be considered. The integration row refers to mapping the creator of the object to the internal data model.
For every system, a different request has to be formulated, either in the form of a list of parameters or in the form of a query. The main source of knowledge regarding which parameters and queries can be used is the documentation of endpoints. Writing adequate documentation is a key aspect for institutions if they want developers from outside their institution to be able to work with the exposed data. In our experience, there is a lot of variation in the completeness and ease of accessing documentation, making the retrieval of data harder than it should be. Table 2 provides an overview of how four of the systems provide access to their data, whereby differences have an impact on request formulation, data retrieval and data integration.
Data retrieval
An approach regularly used to obtain data for collection integration and aggregation is to download dumps of underlying databases, convert data into one format and load this in a new database (Schreiber et al., 2006; Matsumura et al., 2012; Isaac & Haslhofer, 2013). This is a justifiable choice for stable datasets, since changes will not be missed. Another advantage of this approach is that the availability of data does not depend on other systems. However, the data used within the DigiBird project comes from dynamic systems, as a continuous stream of crowd contributions alters and extends the datasets. Since one of our goals is to make crowd contributions instantaneously available, we have to directly access underlying systems to be able to incorporate updated content immediately.
Relevant for data retrieval are the differences in types of endpoints and supported methods for matching objects to request. A common approach is to provide an Application Program Interface (API), which specifies a set of actions that an application can undertake to interact with data. The API providing access to the metadata of Stichting Natuurbeelden does not include scientific names and is formulated in Dutch. This means that we have to rely on “text search” of descriptions in combination with the Dutch label of the concept, in this case “Ekster” for “Eurasian Magpie.” Xeno-canto also uses an API (http://www.xeno-canto.org/article/153) to provide access to their data, but supports parameters stating the genus and species. These two parameters allow us to search for scientific names that are present in the metadata of collection objects. This allows for far more specific retrieval of objects related to the user query, as now we can for example directly query for Pica pica.
The Rijksmuseum and Accurator provide access to data using a public query endpoint that supports SPARQL queries (https://datahub.io/dataset/rijksmuseum/). Although the query endpoints and underlying data models are similar, there is still a difference in how queries can be formulated. The Rijksmuseum artworks are not linked to concepts from the IOC vocabulary. To retrieve relevant artworks from the collection we use a text query that selects objects that include the common name in their description. This method is prone to ambiguity issues, since some of the names of birds also refer to other types of concepts in descriptions. For example, the Dutch name for the “Great Bustard” is “grote trap,” which translates to “big staircase,” thus when performing a query for such a bird, one might retrieve objects related to staircases. Within Accurator, the artworks are linked to concepts from the vocabulary, allowing a completely different concept query. This way, a user can search directly for objects annotated with the concepts originating from the structured vocabulary. In Accurator we can, for example, query for the concept with the URI http://purl.org/vocab/ioc/species-pica_pica, which refers to the “Eurasian Magpie.” These two different types of queries have a big impact on performance, as querying for concepts is faster than the text queries.
Data integration
To achieve the goal of integrating complementary results, we convert the data retrieved from institutions into one internal data model. This entails dealing with the different metadata formats: not all collections use standardized metadata schemas, and even the ones that do might use different standards. An alternative choice would be to directly transmit the obtained data without converting it, leaving the problem at the side of the party requesting the data. This would be inconsistent with our goal to create harmonized data and restrains us from outputting the results in different serializations. We therefore chose to convert the obtained data to a standardized data model. For every collection we have to analyze which elements we are representing and how we can model these elements correctly. We outline our rationale for using elements of the Europeana Data Model (http://pro.europeana.eu/edm-documentation) as our data model.
The Rijksmuseum has data about artworks that we want to include in our results. Basic metadata includes the title and creator of a work, for example the painting The Contemplative Magpie, created by Melchior d’Hondecoeter around the year 1678. These three pieces of information can be modelled using the properties dcterms:title, dcterms:creator, and dcterms:created from the Dublin Core Metadata Initiative (http://dublincore.org/). This information would be sufficient if we would only be interested in the real world object. However, we also want to communicate information about an image of this artwork. This image has different metadata, dcterms:creator, which corresponds to the photographer who took the image and dcterms:created to the date the image was taken. The Europeana Data Model uses properties and classes based upon the Object Reuse and Exchange data model (https://www.openarchives.org/ore/) to make a distinction between a real world object and its digital representation. An aggregation object connects the metadata of the cultural heritage object using the property edm:aggregatedCHO and its digital representation using the property edm:hasView. The Rijksmuseum collection is the most conventional online cultural heritage collection that we use in the DigiBird systemm and modeling the other collections brings new modeling challenges.
Xeno-canto collects recordings of bird sounds, which leads us to ask the conceptual question: is the primary entity the sound or is it the recording of the sound? The sound itself is not persistent, it occurred at a certain point in time and space, which we can describe as an event. The creator of the sound is the bird and the recording is a representation of possibly multiple bird sounds. Additionally, consider as an example the analogy of a still life of a vase containing flowers. Is this a representation of a flower created by the painter, making the flower the cultural heritage object, or is the still life the cultural heritage object with the flower as subject? For the DigiBird system we consider the recording the primary entity. This makes the recordist the creator and allows us to still capture metadata about the time and place the sound was recorded, while the bird is the subject of the recording. A particular view of the recording is the sound file hosted by Xeno-canto.
The Dutch Species Register documents all species in the Netherlands and includes images of specimens. The register is structured according to the biology taxonomy. A modelling choice would be to consider a species to be the primary entity, making images of the species views. This choice however leads to overgeneralization, since the images are taken at a specific point in time and space, while they show specimens of the species. If we would take the species as primary entity, its creator and creation date would be hard to pinpoint. For the DigiBird system, we instead chose the image to be our primary entity and we can record the metadata of the image.
Data output
The data outputted by the DigiBird pipeline can be divided into three categories: objects, annotations, and aggregate information. The discussed pipeline as described up to now concerned the retrieval and integration of objects. Annotations are retrieved in a similar fashion and extend object data. An annotation is structured according to the Web Annotation Model (https://www.w3.org/TR/annotation-model/) and includes information regarding its creator and its creation date. The annotations are sorted by creation date and can be limited by providing a date range.
For the monitoring of progress of crowdsourcing systems, we are interested in a different level of the data: aggregate information regarding number of objects, contributions, and contributors. The pipeline to obtain this information is similar to obtaining objects. For the systems with a public endpoint, it is possible to write a count query obtaining the aforementioned information. For the systems offering an API, separate requests have to be available for obtaining this information. Some of the systems already supported requests for aggregate information, but for others this had to be created.
The outputted format of the data is determined by the type of request. Three options can be used for formatting the data: requesting it as RDF, HTML or as a JSON reply. If someone browses to a DigiBird URL and provides the name of a species (e.g. http://www.digibird.org/species?genus=pica&species=pica), objects related to that species are returned. If a developer requests the same species, but adds in the accept header that this should be in a different format, the DigiBird system supports this. It is possible to output the internal representation of data into different formats. In the next section we discuss examples of using the data.
Using crowd contributions and integrated results
For cultural heritage institutions, it is often a hurdle to incorporate the results of crowdsourcing projects into the institution’s existing digital infrastructure. There are two main reasons for this. Firstly, crowdsourcing projects tend to be short-lived; they run for a limited time, with limited resources, often in a research or “pilot” context. Secondly, they are often hosted on specialized platforms that are not directly connected to the core infrastructure of the institution. Examples of specialized crowdsourcing platforms born and used in the heritage sector include Many Hands (Noordegraaf et al., 2014), Zooniverse (https://www.zooniverse.org), Steve.Museum, but also the Accurator and Waisda? platforms used in DigiBird. After a crowdsourcing project ends, the question often arises as how to integrate or connect the results—tags, annotations, user-generated multimedia, etc.—into the collection management systems and online collection portals.
To overcome this challenge for the crowdsourcing platforms of DigiBird, we chose to connect these platforms by building an API on top of the DigiBird pipeline (https://github.com/rasvaan/digibird_api). This API can be used by heritage institutions to embed the results of the combined crowdsourcing project results directly into their online collections. This way, institutions can connect the results of their own crowdsourcing projects to their online collections in one platform (e.g. connect Waisda? results to Natuurbeelden or Accurator results to the Rijksmuseum collection). Moreover, institutions can embed relevant results from other crowdsourcing projects in their own online collection portals as well, causing real-time cross-pollination of projects otherwise undertaken in isolation.
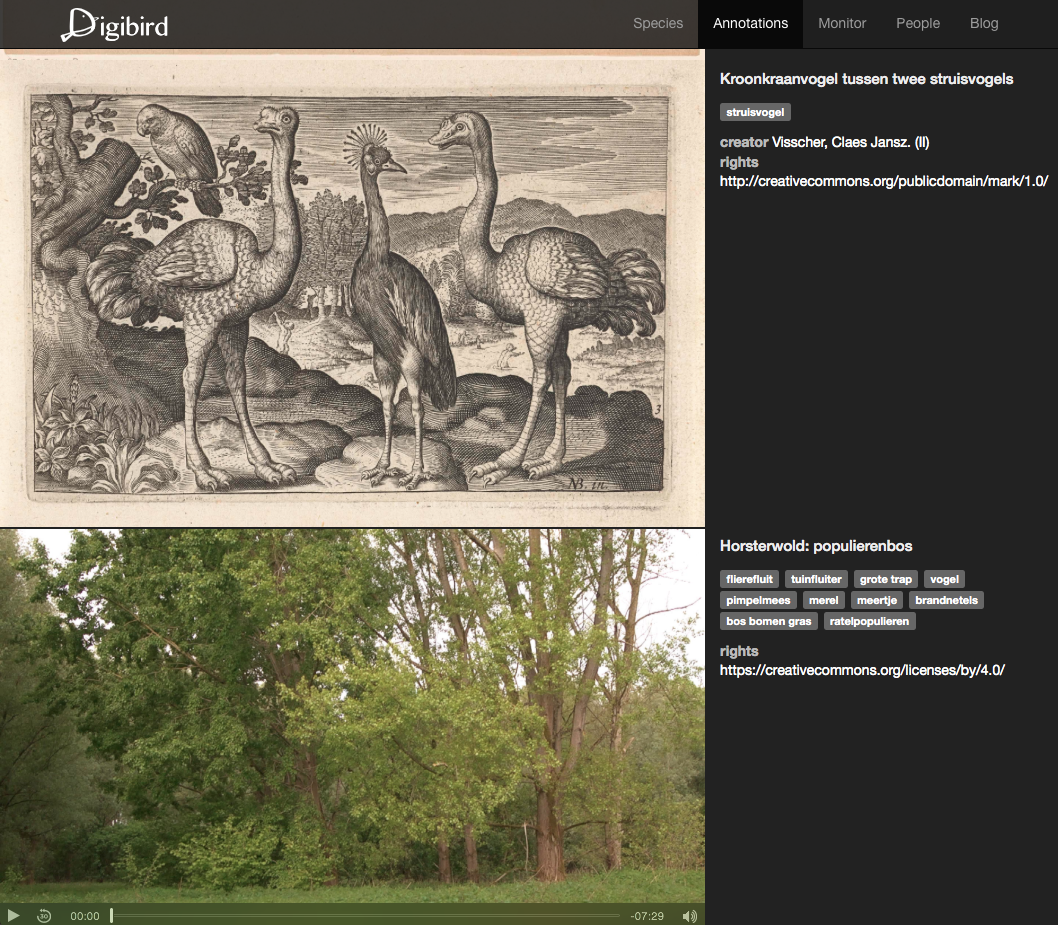
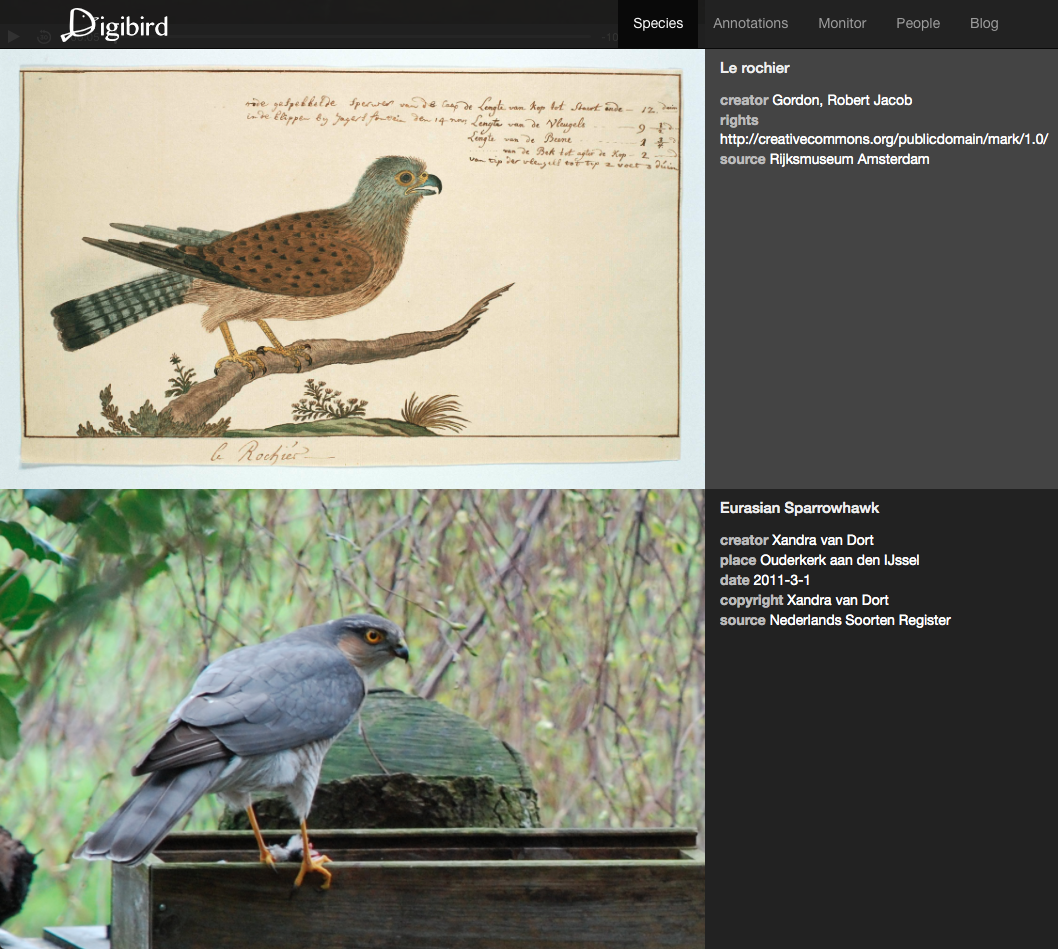
To showcase the functionality of the DigiBird pipeline we build a demonstrator (http://www.digibird.org) with an annotation wall and species search interface (https://github.com/rasvaan/digibird_client). Figure 2 shows a screenshot of the search interface where a user can enter a bird species, which is autocompleted with resources from the IOC World Bird List. Results obtained from the participating institutions are shown side by side, providing the user an overview of different types of media available from different sources regarding their search query. Results are shown the moment they are available, illustrating time differences in retrieving information between the systems. For example, the artworks from the Rijksmuseum often take over a minute to be displayed, due to the slow text query. Figure 3 depicts the annotation wall, which shows a real time overview of crowd contributions. At the moment a contributor adds an annotation in Accurator (http://annotate.accurator.nl/) or tags a video in Waisda? (http://waisda.beeldengeluid.nl), this is immediately displayed on the annotation wall.
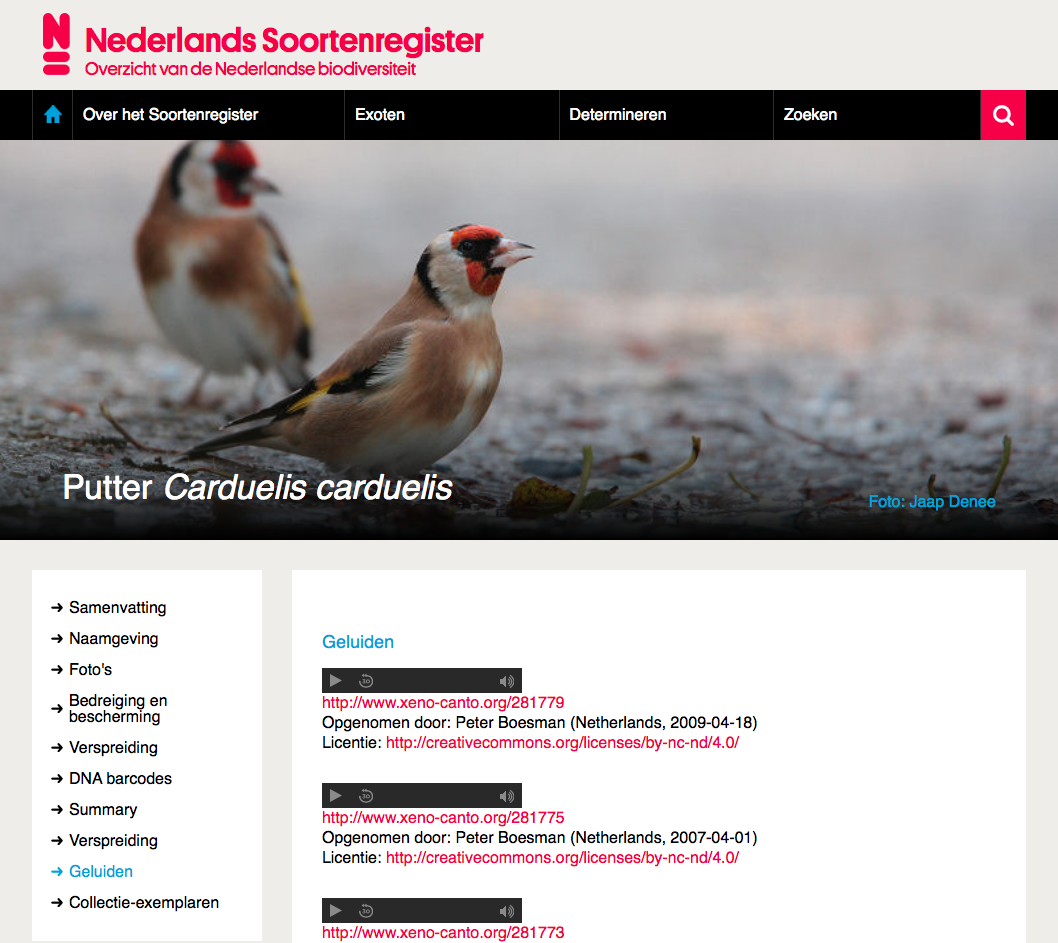
As an example of a use case of the DigiBird API by a cultural heritage institution, the API is used by Naturalis Biodiversity Center to embed crowdsourced bird sounds from the Xeno-canto project on bird species information pages of their Dutch Species Register. An example of this is shown in figure 4. The benefits are bidirectional: Xeno-canto and their contributors have their user-generated content automatically show up in a relevant external portal (causing more exposure and opportunities for feedback) and the Dutch Species Register gets fed relevant external content to automatically enrich its species information pages. Following this example, Naturalis Biodiversity Center could just as well embed crowd-identified bird videos from the Stichting Natuurbeelden on the Dutch Species Register, or Rijksmuseum could enrich the viewing experience of their bird artworks with sounds of the depicted species from Xeno-canto. With each extra platform connected to the DigiBird pipeline, the list of possible cross-references between crowdsourcing initiatives to be explored grows. On top of that, the opportunities for generation of relevant crowdsourcing tasks to expose to potential contributors also grows, adding to the exposure and promotions of such crowdsourcing endeavors.
Discussion and future work
Cultural heritage institutions can benefit greatly from collaborations with other institutions as well as with the public. Considering the current tendency of institutions to publish collection data on the Web, online collaborations might seem an easy feat to accomplish. While DigiBird manages to integrate four collections extended with crowdsourced data, during the course of the project we had to overcome hurdles regarding data retrieval, linking of objects, and data completeness.
Data retrieval and integration is hampered by the diversity of data publishing methods. Within this project we use APIs as well as public query endpoints. All of them provide access to cultural heritage data, although each one takes a different approach regarding accepted requests and formulated responses. This lack of standardization makes integrating collections from multiple sources a cumbersome task and underlines the importance of documentation. By requesting data from APIs, we had to adhere to the limits set by the programmers implementing the API. Uncommon requests had to be tailor made or were simply unavailable. The two query endpoints provided a higher level of flexibility, since they allow the formulation of custom requests. However, compared to the APIs, this comes at the cost of overall performance with respect to responsiveness.
The creation of links between objects is required to provide integrated access to objects from different collections. There are two main approaches for achieving this: by creating direct links between objects or by linking objects to a vocabulary shared by multiple collections. The former approach requires the labor intensive process of creating explicit links between objects every time a new collection is considered. In DigiBird, we take the latter approach and we base the integration on a list of bird names, which serves as the “glue” between the collections. Although initiatives such as the Getty Vocabularies (Baca & Gill, 2015) improve the availability of concepts to link to, not all topics will have such a clear cut choice of a suitable vocabulary available.
Crowdsourcing is evolving to be a valuable approach for cultural heritage institutions to collect data. The DigiBird project is a hub for four distinct crowdsourcing projects. Not undertaking these projects in isolation allows the sharing of resources and provides insights regarding the time needed to collect data. The DigiBird API directly outputs data obtained from the different crowdsourcing projects. As a result, institutions can decide to use data in an early stage of the crowdsourcing process. While this makes it more difficult to ensure a sufficient level of quality, it contributes to a sense of progress and gratification of the crowd contributing to the projects. This DigiBird API is currently used by the Dutch Species Register, embedding content from other sources on the website.
In the future, DigiBird can contribute to the challenge of addressing the promotional effort required to successfully run a crowdsourcing campaign. Based on available data, an assessment can be made of the completeness of metadata. If the metadata of an object is deemed incomplete, a tailored crowdsourcing task could be formulated. Sharing these tasks through an API would allow institutions to embed crowdsourcing tasks on their websites in a similar fashion as collection objects. Thereby moving beyond collaborations on the level of collection items towards engaging audiences in an integrated crowdsourcing approach.
Acknowledgements
DigiBird is a multidisciplinary effort and would not have been possible without the help of the following enthusiastic crowd: From Naturalis Biodiversity Center we would like to thank Maarten Heerlien for his help in getting this project started and Maarten Schermer for integrating the DigiBird API into the Dutch Species Register. We thank Jonathon Jongsma for his work on the Xeno-canto API and from the Rijksmuseum we would like to thank Saskia Scheltjens and Lizzy Jongma. We thank Laurens Rietveld from Triply for his enthusiasm and Javascript skills. Special thanks goes out to the people from Netherlands Institute of Sound and Vision, who kindly hosted the project team and where Jaap Blom and Danny Sedney helped us out with technical support and Saskia Arentsen helped us access the Natuurbeelden collection. This publication was supported by the Dutch national program COMMIT/.
References
Baca, M. & M. Gill. (2015). “Encoding multilingual knowledge systems in the digital age: the Getty vocabularies.” Knowledge Organization 42(4), 232-43.
Brinkerink, M., C. Dijkshoorn, H. Hövelmann, S. Pieterse, & M. Heerlien. (2014). “Bridging the natural divide: Crowd-curation of cultural expressions inspired by nature.” Panel presentation MCN2014, Open Data/Participation Track. Consulted January 12, 2017. Available https://www.youtube.com/watch?v=kU3dd3Kyi3o
Chun, S., R. Cherry, D. Hiwiller, J. Trant, & B. Wyman. (2006). “Steve.museum: an ongoing experiment in social tagging, folksonomy, and museums.” In J. Trant & D. Bearman (eds.). Museums and the Web 2006: Proceedings. Toronto: Archives & Museum Informatics, 2006. Published March 1, 2006. Consulted January 12, 2017. Available http://www.archimuse.com/mw2006/papers/wyman/wyman.html
Dijkshoorn, C., L. Jongma, L. Aroyo, J. Van Ossenbruggen, G. Schreiber, W. ter Weele, & J. Wielemaker. (2017 in press). “The Rijksmuseum collection as Linked Data.” Semantic Web Journal. Consulted January 12, 2017. Available http://www.semantic-web-journal.net/content/rijksmuseum-collection-linked-data-2
Gligorov, R., M. Hildebrand, J. Ossenbruggen, L. Aroyo, & G. Schreiber. (2013). “An evaluation of labelling-game data for video retrieval.” In P. Serdyukov, P. Braslavski, S. Kuznetsov, J. Kamps, S. Rüger, E. Agichtein, I. Segalovich, & E. Yilmaz (eds.). Advances in Information Retrieval. Berlin: Lecture Notes in Computer Science. 50-61.
Isaac, A. & B. Haslhofer. (2013). “Europeana Linked Open Data – data.europeana.eu”. Semantic Web Journal 4(3), 291-97. Consulted January 12, 2017. Available http://www.semantic-web-journal.net/content/europeana-linked-open-data-–-dataeuropeanaeu
Jongma, L. & C. Dijkshoorn. (2016). “Accurator: Enriching collections with expert knowledge from the crowd.” MW16: Museums and the Web 2016. Published February 7, 2016. Consulted January 12, 2017. http://mw2016.museumsandtheweb.com/paper/accurator-enriching-collections-with-expert-knowledge-from-the-crowd/
Matsumura, F., I. Kobayashi, F. Kato, T. Kamura, I. Ohmukai, & H. Takeda. (2012). “Producing and consuming Linked Open Data on art with a local community.” In J. Sequeda, A. Harth & O. Hartig (eds.). Proceedings of the third international workshop on consuming Linked Data. Boston: CEUR Workshop Proceedings. Consulted January 12, 2017. Available http://ceur-ws.org/Vol-905/MatsumuraEtAl_COLD2012.pdf
Noordegraaf, J., A. Bartholomew & A. Eveleigh. “Modeling Crowdsourcing for Cultural Heritage.” MW2014: Museums and the Web 2014. Published February 17, 2014. Consulted January 13, 2017. http://mw2014.museumsandtheweb.com/paper/modeling-crowdsourcing-for-cultural-heritage/
Oomen, J. & L. Aroyo. (2011). “Crowdsourcing in the cultural heritage domain: opportunities and challenges.” In M. Foth, J. Kjeldskov & J. Paay (eds.). Proceedings of the fifth international conference on communities and technologies. New York: ACM Press. 138-49.
Schreiber, G., A. Amin, M. Van Assem, V. De Boer, L. Hardman, M. Hildebrand, L. Hollink, Z. Huang, J. van Kersen, M. de Niet, B. Omelayenko, J. van Ossenbruggen, R. Siebes, J. Taekema, J. Wielemaker, & B. Wielinga. (2006). “Multimedian e-culture demonstrator.” In I. Cruz, S. Decker, D. Allemang, C. Preist, D. Schwabe, P. Mika, M. Uschold & L. Aroyo (eds.). Proceedings of the fifth international semantic web conference. Athens: Lecture Notes in Computer Science. 951-58.
Cite as:
Dijkshoorn, Chris, Cristina-Iulia Bucur, Maarten Brinkerink, Sander Pieterse and Lora Aroyo. "DigiBird: On the fly collection integration supported by the crowd." MW17: MW 2017. Published January 14, 2017. Consulted .
https://mw17.mwconf.org/paper/digibird-on-the-fly-collection-integration-supported-by-the-crowd/